Как создать pandas DataFrame
DataFrame — это специальная структура данных в очень популярной Python библиотеки pandas. Работа с библиотекой pandas часто заключается в том что нужно создать из данных DataFrame, а дальше что-то делать с этими данными, лежащими в DataFrame.
Есть несколько способов создать DataFrame.
Создать DataFrame из данных, записанных в коде программы
Самый простой способ создать DataFrame — это передать конструктору словарь. Ключи станут названиями колонок, а значения (в которых содержатся списки) станут данными в этих колонках.
import pandas as pd
df = pd.DataFrame({'name': ['Earth', 'Moon', 'Mars'], 'mass_to_earth': [1, 0.606, 0.107]})
Вот пример как это выглядит в Jupyter Notebook:
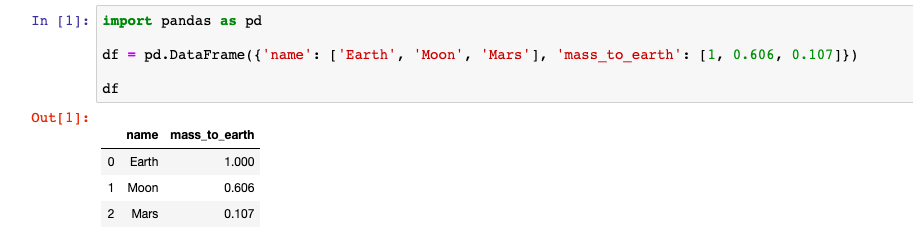
Но не всегда удобно задавать данные по столбцам. Можно создать DataFrame и из данных, которые разбиты по строкам. Для этого в конструктор нужно передать список в котором содержатся данные для строк. Вот пример создания DataFrame с данными как из прошлого примера, но по строкам, а не по столбцам:
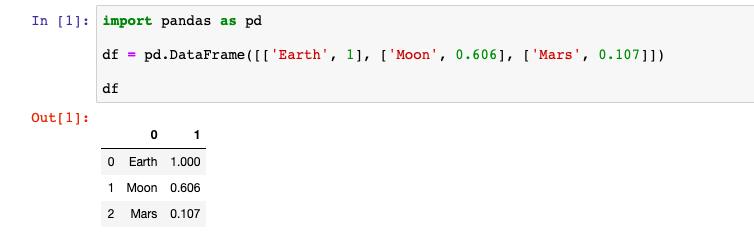
df = pd.DataFrame([['Earth', 1], ['Moon', 0.606], ['Mars', 0.107]])
Но при такой записи система не знает как нужно называть столбцы, поэтому названия столбцов становятся числа начиная с нуля. В этих данных две колонки, поэтому они называются ноль и один:
Для того чтобы вместо чисел были осмысленные названия колонок нужно указать список названий в именованном аргументе columns:
df = pd.DataFrame([['Earth', 1], ['Moon', 0.606], ['Mars', 0.107]], columns=['name', 'mass_to_earth'])
Но запись данных в коде программы подходит только для очень простых ситуаций, когда данных немного. Обычно данные в DataFrame загружаются из какого-то внешнего источника, например из файла из из базы данных.
Создать DataFrame из csv файла
Вот содержимое файла solar-system.csv:
name,mass_to_earth
Earth,1
Moon,0.606
Mars,0.107
Csv — это очень распространенный формат (расшифровывается как "comma separated values",— "значения разделенные запятыми"). В файле solar-system.csv в первой строчке находится заголовок с названиями столбцов, все остальные строки — это данные. Разделитель между элементами это символ запятая. Для того чтобы загрузить данные из этого файла в DataFrame нужно сказать:
df = pd.read_csv('solar-system.csv')
Но иногда формат csv файла выглядит несколько иначе. Бывает что в качестве разделителя используется не запятая, а какой-то другой символ, например точка с запятой или символ табуляции (в это случае файл иногда бывает с расширением .tsv — "tab separated values"). read_csv можно указать какой разделитель использовать:
df = pd.read_csv('solar-system.tsv', sep='\t')
Бывает что в csv файле нет заголовка, в первой строке сразу идут данные. В таком случае нужно передать None в именованный параметр header:
df = pd.read_csv('solar-system.csv', header=None)
Но в такой ситуации система не будет знать какие названия столбцов использовать и будут использованы цифры начиная с нуля. Для того чтобы установить имена колонок нужно передать параметр names:
df = pd.read_csv('solar-system.csv', header=None, names=['name', 'mass_to_earth'])
Создать DataFrame из jsonl файла
Кроме csv еще есть достаточно популярный формат для хранения данных в текстовых файла — jsonl. JSON Lines. При использовании этого формата в каждой строчке файла содержится однострочный json. Это формат лучше чем csv, так как строго регламентирует что должно быть разделителем и как нужно экранировать.
Вот пример содержимого файла solar-system.jsonl:
{"name":"Earth","mass_to_earth":1}
{"name":"Moon","mass_to_earth":0.606}
{"name":"Mars","mass_to_earth":0.107}
Для того чтобы загрузить его в DataFrame нужно сказать:
pd.read_json('solar-system.jsonl', lines=True)
Создать DataFrame из результата sql запроса
Вот пример кода, который загружает в DataFrame таблицу с результатом sql запроса из sqlite базы данных:
import sqlite3
import pandas as pd
cnx = sqlite3.connect(r'/data/db.db')
df = pd.read_sql_query("SELECT * FROM users", cnx)
Создать DataFrame из файла в интернете
Иногда необходимо создать DataFrame с данными которые лежат где-то в интернете. Например, создать DataFrame из csv файла, который лежит на GitHub.
pandas.read_csv умеет рабоать не только с локальными файлами, но и с файлами, которые лежат в интернете. Вот как загрузить в DataFrame данные про страны из файла по ссылке:
import pandas as pd
url = 'https://raw.githubusercontent.com/lukes/ISO-3166-Countries-with-Regional-Codes/master/all/all.csv'
df = pd.read_csv(url)
Дальше
10 декабря 2019
