Perl массивы
Массив в языке Perl — это переменная, которая содержит в себе список значений. Имя переменной массива начинается с символа @. И это достаточно логично — символ @ основан на букве a, именно с этой буквы начинается слово array — массив.
Массив в Perl может хранить в себе список значений любых типов. Может быть массив в котором одновременно хранятся и строки, и числа, и что-нибудь еще.
Определение массива и доступ к элементам
Вот простой скрипт с примером определения и использования элементов массива в Perl:
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use feature 'say';
my @names = ('Homer', 'Marge', 'Bart', 'Lisa', 'Maggie');
say $names[0];
say $names[2];
Если запустить этот скрипт, то он выведет на экран:
Homer
Bart
Что здесь происходит. Сначала стандартная строка с которой начинаются все Perl скрипты #!/usr/bin/perl, потом идет подключение (use) нескольких фич языка, которые делают работу с Perl удобнее. А потом создается переменная @names и ей присваивается список из 5 строк.
my @names = ('Homer', 'Marge', 'Bart', 'Lisa', 'Maggie');
Как и во многих языках программирования в Perl первый элемент массива получает номер 0. После выполнения этой операции в переменной @names оказывается следующее:
- в этой переменной под номером 0 хранится строка 'Homer'
- под номером 1 хранится строка 'Marge'
- 2 — 'Bart'
- 3 — 'Lisa'
- 4 — 'Maggy'
Для того чтобы достать из переменной @name элемент с номером 2 используется совершенно идиотская форма — $name[2]. Вот тут супер нелогично что символ @ заменятся на символ $ Официальное объяснение этой глупости — мы хотим получить доступ к одному элементу, а переменная с одним элементом начинается с символа $ Но это просто ошибка в дизайне языка. В Perl версии 6 это исправлено. Но в Perl версии 5 приходится жить с этим.
Строка
say $names[0];
говорит — выводи на экран то что находится в массиве под номером 0. Под номером 0 в массиве находится строка 'Homer' — она и появляется на экране.
Определение массивов. Дополнение.
Только что мы определи массив с помощью такого кода:
my @names = ('Homer', 'Marge', 'Bart', 'Lisa', 'Maggie');
Когда элементов в массиве много, то удобнее их писать в столбик:
my @names = (
'Homer',
'Marge',
'Bart',
'Lisa',
'Maggie'
);
В языке Perl нет проблемы JSON — в Perl разрешено указывать запятую после последнего элемента:
my @names = (
'Homer',
'Marge',
'Bart',
'Lisa',
'Maggie',
);
(На самом деле, если вы перечисляете элементы массива в столбик, то стоит всегда указывать запятую после последнего элемента — это делает проще работу с кодом и упрощает чтение diff).
Если в массиве находятся строки текста в которых нет пробелов, то есть еще более простой способ определить массив — использовать оператор qw:
my @names = qw(
Homer
Marge
Bart
Lisa
Maggie
);
Оператор qw разрезает текст который ему передан по пробельным символам и создает элементы списка.
Если нужно создать массив из списка чисел которые идут подряд, то можно использовать оператор ..
my @array = (1..5);
Это то же самое что:
my @array = (1, 2, 3, 4, 5);
Оператор .. так же работает с буквами:
my @array = ('a'..'z');
Эту фичу языка можно использовать в простом perl однострочнике, для генерации паролей:
$ perl -E '@c = ("a".."z", "A".."Z", 0..9); $s .= $c[rand(@c)] for (1..12); say $s'
eIryv0884sp7
Вывод массивов
Иногда во время разработки программы нужно посмотреть что находится внутри массива. Для этого можно использовать библиотеку Data::Dumper:
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use feature 'say';
my @names = ('Homer', 'Marge', 'Bart', 'Lisa', 'Maggie');
use Data::Dumper;
say Dumper \@names;
Вот вывод этого скрипта:
$VAR1 = [
'Homer',
'Marge',
'Bart',
'Lisa',
'Maggie'
];
Если у вас есть Perl, то у вас библиотека Data::Dumper. Но если вы поставите дополнительно библиотеку Data::Printer, то для вывода содержимого массива придется писать меньше букв:
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use feature 'say';
my @names = ('Homer', 'Marge', 'Bart', 'Lisa', 'Maggie');
use DDP;
p \@names;
И вывод скрипта гораздо приятнее:
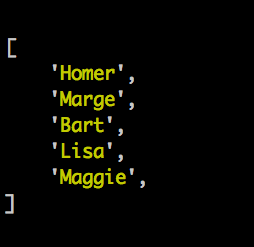
Дополнительная информация про Data::Printer.
Длина массива
Задача. У нас есть массив @names, нужно узнать его размер — сколько в нем находится элементов. Есть несколько способов это сделать. Можно использовать специальную переменную в которой содержится индекс последнего элемента, а можно воспользоваться фичей Perl под названием "контекст".
Когда появляется массив, автоматически появляется специальная переменная, которая указывает на индекс последнего элемента. У нас есть массив @names в котором содержится 5 элементов и для него существует переменная $#names в которой содержится число 4 (так как элементы нумеруются с 0, а не с 1). Если количество элементов в массиве изменится, то автоматически изменится и $#names.
Первый способ узнать количество элементов в массиве — это взять $#names и прибавить единицу:
say $#names + 1;
Этот способ работает и совершенно корректен, но более правильный способ — это использовать "контекст":
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use feature 'say';
my @names = ('Homer', 'Marge', 'Bart', 'Lisa', 'Maggie');
my $number = @names;
say $number;
Что же здесь происходит? Сначала все то же самое что и в прошлом скрипте, но потом выполняется:
my $number = @names;
Мы создаем новую переменную $number В начале имени этой переменной находится символ $ — это означает что тип этой переменной — скаляр. Символ $ совершенно логичен — это символ похож на букву s с которой начинается слово scalar. Скаляр или скалярная переменная — это переменная в которой содержится только одно значение. Это может быть строка, число или что-нибудь еще.
И тут появляется контекст. Контекст — это весьма важная вещь в языке программирования Perl. В языке Perl в зависимости от контекста (т.е. от того что рядом) разные вещи действуют по разному. Контекст — это сложная вещь. Но для того чтобы программировать на Perl нужно разобраться ка работает контекст.
Выражение my $number = @names; означает что мы взяли массив и использовали его в "скалярном контексте". В скалярном контексте массива — это количество элементов в нем, т.е. ровно то что мы хотели получить.
Вот еще один пример использования контекста. Можно использовать массив в списочном контексте:
my ($man, $woman) = @names;
Результат этой операции — в скалярной переменной $man будет находится строка 'Homer', а в скалярной переменной $woman будет находится строка 'Marge'.
В скрипте мы сначала присваивали массив в скалярную переменную, а потом выводили значение этой переменной:
my $number = @names;
say $number;
А что будет если сразу вывести на экран значение массива @names ?
say @names
Вот результат:
HomerMargeBartLisaMaggy
Такой вывод сильно отличается от числа 5. Объяснение этому — контекст. Ключевое слово say работает в списочном контексте. say выводит на экран все элементы списка который ей передали. Но можно явно указать что мы хотим работать с массивом в скалярном контексте:
say scalar @names;
В этом случае вывод будет 5.
Работа с массивом
Бывают задачи когда нужно только создать массив, а дальше только читать из него значения. Но чаще встречаются задачи когда массив нужно изменять. Для этого есть несколько удобных функций.
Добавление элемента в конец массива:
my @arr = (1, 2, 3);
push @arr, 'abc';
Результат этой операции — в массиве @arr будет список (1, 2, 3, 'abc');
С помощью push можно добавить в массив несколько элементов:
my @arr = (1, 2, 3);
push @arr, 'abc', 'def';
Результат этой операции — в массиве @arr будет список (1, 2, 3, 'abc', 'def');
Интересная особенность push, про которую мало кто знает — эта функция не только меняет массив, но еще и возвращает число — сколько элементов стало в массиве после добавления в массив всех указанных элементов. Так что задачу "найти количество элементов в массиве" можно решить вот таким супер извращенным способом:
my $number = push(@arr, 1) - 1;
Функция push добавляет элемент (или элементы) в конец массива. В Perl есть функция для обратной операции — достать из массива последний элемент. Это делается с помощью функции pop (с помощью этой функции достать несколько элементов нельзя, эта функция достает только один элемент).
my @arr = (1, 2, 3);
my $smth = pop @arr;
После выполнения кода выше массив @arr будет состоять из двух элементов (1, 2), а в переменной $smth будет находится число 3.
С помощью функций push/pop можно работать с массивом как со стеком.
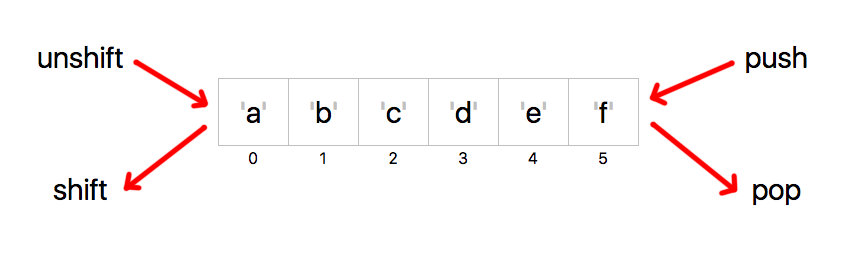
Кроме функций push/pop, которые добавляют/убирают элементы в конце массива еще есть функции shift/unshift, которые работают с началом массива.
Добавить элемент в начало массива:
my @arr = (1, 2, 3);
unshift @arr, 'abc';
После выполнения этих команд в массиве @arr будет находится список ('abc', 1, 2, 3)
С помощью unshift можно добавить несколько элементов в начало массива:
my @arr = (1, 2, 3);
unshift @arr, 'abc', 'def';
После выполнения этих команд в массиве @arr будет находится список ('abc', 'def', 1, 2, 3)
Точно так же как push, unshift возвращает число — количество элементов в массиве после добавления туда всех элементов.
Достать из массива первый элемент можно с помощью функции shift:
my @arr = (1, 2, 3);
my $element = shift @arr;
После выполнения этих действий массив станет состоять из двух элементов (2, 3), а в переменной $element будет бывший первый элемент массива — число 1.
Итого:
- unshift добавляет элемент/элементы в начало массива
- shift достает элемент из начала массива
- push добавляет элемент/элементы в конец массива
- pop достает элемент из конца массива
Итерация по массиву
Часто бывают задача — нужно пробежаться по всем элементам массива и выполнить с ними какое-то действие.
В Perl, как и во множестве других языков программирования есть цикл for. Вот как пройти по всем элементам массива с помощью for:
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use feature 'say';
my @names = ('Homer', 'Marge', 'Bart', 'Lisa', 'Maggie');
for (my $i = 0; $i <= $#names; $i++) {
say $names[$i];
}
Вот вывод этой программы:
Homer
Marge
Bart
Lisa
Maggie
Тут все стандартно и просто. Определили $i = 0, проверили что условие выполняется, выполнили тело цикла, увеличили счетчик, проверили что условие выполняется, выполнили тело цикла, увеличили счетчик, ...
Но Perl предоставляет более простой и удобный способ итерации по массиву:
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use feature 'say';
my @names = ('Homer', 'Marge', 'Bart', 'Lisa', 'Maggie');
foreach my $name (@names) {
say $name;
}
В этом варианте в переменную $name по очереди заносятся все элементы массива. Такой вариант проще и читать, и писать.
В Perl есть интересная фича — переменная по умолчанию. Если ну указать переменную для foreach, то perl будет заносить все элементы массива в переменную по умолчанию $_ :
foreach (@names) {
say $_;
}
А если для say не указать никаких параметров, то say будет работать с переменной по умолчанию. Так что этот же цикл можно написать так:
foreach (@names) {
say;
}
А еще в Perl можно использовать постфиксную запись для foreach, поэтому этот же цикл можно записать:
say foreach @names;
В Perl есть цикл while, и его тоже можно использовать для итерации по массиву. Например так (аккуратно, в таком использовании кроется опасность):
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use feature 'say';
my @names = ('Homer', 'Marge', 'Bart', 'Lisa', 'Maggie');
while (my $name = shift @names) {
say $name;
}
Конкретно этот пример работает точно так же как и другие варианты в этом разделе. Но если в массиве есть undef элементы, то этот цикл не пройдет по всем элементам:
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use feature 'say';
my @names = ('Homer', 'Marge', 'Bart', 'Lisa', undef, 'Maggie');
while (my $name = shift @names) {
say $name;
}
Вывод этого скрипта:
Homer
Marge
Bart
Lisa
Т.е. без 'Maggie'. Можно переделать цикл while чтобы он работал корректно, например, так:
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use feature 'say';
my @names = ('Homer', 'Marge', 'Bart', 'Lisa', undef, 'Maggie');
while ($#names != -1) {
my $name = shift @names;
say $name if $name;
}
(Переменная $#names возвращает -1 в том случае если массив пустой).
Но проще и понятнее это было бы написать с помощью foreach:
foreach (@names) {
say if $_;
}
Функции
Массивы в Perl используются при написании собственных функций:
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use feature 'say';
sub say_hello {
my ($name) = @_;
say "Hello, ", $name;
}
say_hello 'Homer';
Тут определяется функция с именем say_hello. Когда мы ее вызываем, то внутри функции все параметры которые мы в нее передали попадают в специальный массив @_.
С помощью записи
my ($name) = @_;
мы сохранили первый элемент массива @_ в переменную $name.
@_ — это массив, так что можно было работать с ним иначе. Например так:
sub say_hello {
say "Hello, ", $_[0];
}
Или так:
sub say_hello {
my $name = shift @_;
say "Hello, ", $name;
}
Если использовать shift внутри sub и не указать ей параметры, то она будет работать с @_. Так что последний вариант можно было записать:
sub say_hello {
my $name = shift;
say "Hello, ", $name;
}
25 февраля 2017
