Язык Perl и Unicode
Сейчас 2013 год и для того чтобы не было проблем с кодировками, разными языками, интернационализацией и локализацией, следует везде где только можно использовать кодировку utf8. Кодировка utf8 — это самая популярная кодировка из большого стандарта Unicode.
В языке Perl все очень хорошо с поддержкой utf8, но чтобы работать с этой кодировкой нужно чуть-чуть понимать как это все устроено (такие сложности идут от того что Perl очень трепетно относится к сохранению обратной совместимости, язык Perl стараются разрабатывать таким образом чтобы программы, написанные для ранних версий языка Perl работали в более поздних версиях Perl).
Базовый пример
Вот очень простой Perl скрипт, котором все написано правильно с точки зрения кодировки:
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use utf8;
use open qw(:std :utf8);
my $string = "абвгдеёжзийклмнопрстуфхцчшщъыьэюя";
print "'" . utf8::is_utf8($string) . "'" . "\n";
print length($string) . "\n";
print $string . "\n";
print uc($string) . "\n";
Вот что выведет этот скрипт:
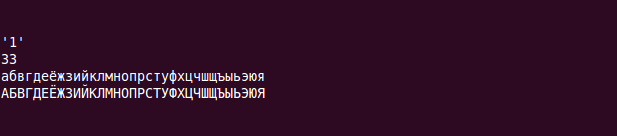
В выводе все идеально. Именно так и должно все быть.
Разберем весь скрипт.
Все штуки "use что-то_там" — это так называемые "прагмы" — штуки, которые как-то изменяют язык Perl (прагмы очень легко узнать — они всегда пишутся маленькими буквами).
"use strict;" и "use warnings FATAL => 'all';" говорит Perl что в случае возникновений даже каких-либо мелких проблем нужно останавливать работу скрипта. Это самое правильное поведение для работы программы — в случае если что-то идет как-то не так, как было предусмотрено программистом, — нужно срочно прекращать работу программы (иначе может сложится очень плохая ситуация, когда программа продолжает работать, но работает неправильно, такая программа может испортить данные или обмануть пользователя).
"use utf8;" говорит Perl что код нашей программа написан в кодировке utf8.
"use open qw(:std :utf8);" говорит Perl что все потоки STDIN, STDOUT, STDERR должны работать с utf8.
"my $string = "абвгдеёжзийклмнопрстуфхцчшщъыьэюя";" — это обыкновенное определение переменной и присвоение ей строки со всеми символами русского алфавита в нижнем регистре.
"print "'" . utf8::is_utf8($string) . "'" . "\n";" — тут мы начинаем что-то делать с переменной. Мы выводим на экран результат работы функции "utf8::is_utf8()". У переменной в Perl есть внутренний флаг, который определяет находится ли значение переменной в кодировке utf8 или нет. В реальной жизни этой функций пользуются очень мало. Обычно ее используют при разработке и дебаге для того чтобы понять что там происходит с utf8 в случае если что-то работает неправильно. В нашем примере эта функция возвращает "1", т.е. "да, значение переменной находится в кодировке utf8".
"print length($string) . "\n";" — выводим на экран длину строки. В нашем случае строка состоит из 33 Unicode символов. В этом случае в качестве результата получаем значение "33".
"print $string . "\n";" — выводим строку на экран. Получаем вполне ожидаемый результат — видим на экране 33 символа русского алфавита.
"print uc($string) . "\n";" — выводим на экран строку, преобразованную к верхнему регистру. То же все понятно. Видим символы русского алфавита в верхнем регистре.
Ошибка 1. Не используем "use utf8;"
Чуть-чуть исправляем правильный пример, убираем "use utf8;":
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
#use utf8;
use open qw(:std :utf8);
my $string = "абвгдеёжзийклмнопрстуфхцчшщъыьэюя";
print "'" . utf8::is_utf8($string) . "'" . "\n";
print length($string) . "\n";
print $string . "\n";
print uc($string) . "\n";
Вот что выведет такой скрипт:
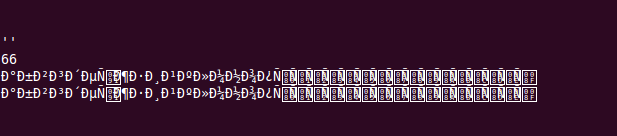
Прагма "use utf8;" говорит Perl что код программы написан в кодировке utf8. Когда мы убираем эту прагму, Perl перестает считать что в переменной $string содержится utf8 и работает с ними просто как с байтами.
Функция "utf8::is_utf8()" возвращает пустую строку, что означает что у переменной нет флага что значение переменной в кодировке utf8.
Функция lenght() возвращает 66. Сейчас она работает со строкой, как с набором байт, а в нашем случае, каждый из 33 Unicode символов кодируется двумя байтами, из-за этого и получилось число 66.
Хочу разобрать почему же выводятся именно такие крякозябры. Разберем первые 2 символа из этого вывода.
В стандарте Unicode русская буква "а" — это символ с номером "0430" (CYRILLIC SMALL LETTER A). В кодировке utf8 этот Unicode символ записывается с помощью двух байт "d0" (это 208 в десятичной системе счисления) и "b0" (это 176 в десятичной системе).
В случае когда мы не указали "use utf8;" Perl выводить каждый байт в виде отдельного символа. Байт "d0" на экране выглядит так:

Байт "b0" на экране выглядит вот так (это скриншоты с википедии):

В случае если не указать "use utf8;" Perl не воспринимает строку как набор Unicode символов, а думает что это набор байт. И выводит каждый байт на экран в виде отдельного символа.
Ошибка 2. Не используем "use open qw(:std :utf8);"
Еще один раз поправим наш работающий пример и уберем из него прагму "use open qw(:std :utf8;)".
Вот скрипт:
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use utf8;
#use open qw(:std :utf8);
my $string = "абвгдеёжзийклмнопрстуфхцчшщъыьэюя";
print "'" . utf8::is_utf8($string) . "'" . "\n";
print length($string) . "\n";
print $string . "\n";
print uc($string) . "\n";
А вот его вывод:

Perl с помощью ошибки "Wide character in print at" предупреждает нас о том что мы пытаемся напечатать utf8 строку куда-то (в данном случае в STDOUT) что не поддерживает utf8. Решается это с помощью включения прагмы "use open qw(:std :utf8);", которая отмечает все стандартные каналы (STDIN, STDOUT, STDERR) для работы с utf8.
Такого же результата можно добиться с помощью функции "binmode()", но для чтобы перевести все каналы на работу с utf8 нужно написать больше строк. Поэтому я предпочитаю вариант "use open qw(:std :utf8);", но такой скрипт тоже правильно отработает:
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use utf8;
binmode STDIN, ":utf8";
binmode STDOUT, ":utf8";
binmode STDERR, ":utf8";
my $string = "абвгдеёжзийклмнопрстуфхцчшщъыьэюя";
print "'" . utf8::is_utf8($string) . "'" . "\n";
print length($string) . "\n";
print $string . "\n";
print uc($string) . "\n";
Ошибка 3. Не используем ни "use utf8;", ни "use open qw(:std :utf8);"
Вот еще одна прекрасная ошибка. Вот скрипт:
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
#use utf8;
#use open qw(:std :utf8);
my $string = "абвгдеёжзийклмнопрстуфхцчшщъыьэюя";
print "'" . utf8::is_utf8($string) . "'" . "\n";
print length($string) . "\n";
print $string . "\n";
print uc($string) . "\n";
Его вывод:
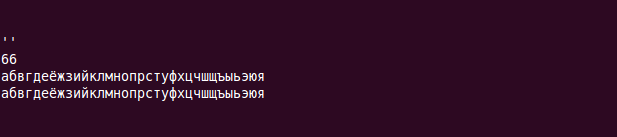
Чудесная проблема. Вроде бы print работает — выводит то что нужно, но length() выдает неправильную длину строки и перевод строки в верхний регистр с помощью функции uc() не работает.
Главная проблема в этом скрипте — это то что Perl не знает что содержимое переменной $string находится в кодировке utf8. Perl считает что эта строка состоит не из Unicode символов, а из байтов. Из-за этого length() выдает количество байт (в этой строке каждый символ закодирован с помощью двух байт).
В верхний регистр перевод не работает опять таки из-за того что Perl не знает что эта строка с символами. Он считает что эта строка из байтов. Первые два байта (байты, которые кодируют русскую букву "а") — это байты "d0" и "b0". Для символов, которые представлены этими байтами нет символов верхнего регистра. Вот скриншоты с википедии этих двух байтов:
Вторая проблема в этом скрипте — это то что каналы вывода не подготовлены к выводу utf8. Эта проблема компенсирует проблему что Perl не знает что это строка в кодировке utf8. Из-за этого print выводит ожидаемую строку, но это ошибка наложенная на ошибку. В выводе-то все правильно, но работать со строкой нельзя — length() и uc() (и все остальные функции для работы со строками) будут работать неправильно.
Дополнительная литература.
Perl и Unicode рассматривается в куче статей. Вот несколько очень хороших статей:
Резюме.
Perl хорошо работает с utf8, но ему нужно ясно указать что мы хотим работать с utf8.
В начале Perl скрипта стоит всегда писать:
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use utf8;
use open qw(:std :utf8);
15 июня 2013
