Как изменилась длина выпусков подкаста Радио-Т за все время
Про подкаст
Есть совершенно замечательный русскоязычный подкаст Радио-Т.
Он уже выходит более 10 лет. Каждую субботу ведется online вещание, а где-то в воскресенье становится доступен mp3 файл с записью.
Основная тема — это ИТ. Основная линия вокруг которой строится рассказ — это обсуждение новостей которые появились за прошлую неделю. Но иногда ведущие отвлекаются от новостей и рассказывают что-нибудь свое, интересненькое.
Много-много лет я с удовольствием слушаю этот подкаст. Это единственный подкаст, который я регулярно слушаю. Основная прелесть — что ведущие это не журналисты, работа которых рассказывать, а люди которые действительно работают в IT и поэтому они понимают что говорят (хотя, не совсем из всего того что они говорят я согласен).
Задача
В одном из недавних выпусков как-то мимолетно упоминали что раньше выпуски были сильно короче.
Мне стало интересно посмотреть, а как менялась длина выпусков за всю историю этого подкаста.
Сейчас есть уже 690 выпусков (астрономическое число). Подкаст выходит раз в неделю, в году приблизительно 52 недели, 690/52 грубо это около 13 лет в эфире.
Так что задача — нарисовать график по оси X — это номер выпуска, по оси Y — это продолжительность выпуска.
Решение
Задача кажется достаточно простой. Есть 690 mp3 файлов, которые лежат где-то в интернете. Нужно для каждого файла узнать его продолжительность в секундах, сохранить это где-то и из этих данных нарисовать график.
Пошел решать.
Я решил в качестве эксперимента решить эту задачу на языке программирования Go. Вообще, это первое что я когда-нибудь делал на языке Go, так что код который получился очень далек от совершенства.
Существует RSS файл https://radio-t.com/podcast.rss в котором есть информация про последние выпуски (Там находится информация про 21 выпуск. Я, конечно, точно не знаю, но то что там 21 выпуск, а не 20, это очень похоже на баг граничных значений).
Плюс есть RSS файл в котором находится информация про архивные выпуски https://radio-t.com/podcast-archives.rss (тут тоже странно, я ожидал что в этом файле будет информация только про те выпуски про которых нет инфы в основном rss файле, но нет, в архивном rss есть и свежие выпуски)
RSS файл — это xml файл в котором про каждый эпизод есть вот такой блок:
<item>
<title>Радио-Т 669</title>
<description>...</description>
...
<itunes:image href="https://radio-t.com/images/radio-t/rt669.jpg" />
<enclosure url="http://cdn.radio-t.com/rt_podcast669.mp3" type="audio/mp3" length="107609962" />
</item>
Вот значение атрибута url у элемента enclosure — это как раз адрес где находится mp3 файл с эпизодом.
Т.е. нужно взять rss файл, достать из него все значения атрибута url скачать этот файл, узнать его длину и записать куда-нибудь.
Где проще всего хранить данные? В файлах! А где проще всего хранить небольшие текстовые файлы? На GitHub!
Так что я решил что результат парсинга mp3 файла я буду складывать в json файл, который будет лежать в каком-нибудь репозитории на гитхабе.
Забегая немного вперед, вот что получилось. Вот пример json файла с данными про один эпизод:
{
"number": 689,
"file": {
"size_bytes": 84848415,
"length_seconds": 7067,
"url": "http://cdn.radio-t.com/rt_podcast689.mp3",
"md5": "ce7bc33158d630547a6ae0ed541efcfc"
}
}
Главное что тут есть — это информация про длину выпуска и номер эпизода (номер эпизода еще есть и в названии json файла). Но кроме этого я еще решил записывать в этот файл еще кое-какую информацию. Размер, ссылка откуда получил файл и еще хеш от этого файла (это для упрощения дебага, если в нем будет необходимость, чтобы можно было легко понять что размер не тот не из-за того что в коде ошибка, а что просто mp3 файл поменялся)
Итак, файлы с данными будут храниться в репозитории на гитхабе. Код который будет эти данные формировать тоже должен быть в репозитории. Вполне можно и код, и данные положить в репозиторий.
Ну и раз все хранится на гитхабе — то почему бы не использовать GitHub Actions чтобы он и выполнял этот код?
Я так и сделал. Написал код, который:
- выкачивает rss файл
- достает оттуда все ссылки на mp3 файлы
- выяснят номер эпизода из названия файла
- проверят, есть ли json файл про такой эпизод (если есть, то это означает что этот эпизод уже обработан)
- если файла нет, то скачивается mp3 файл, выясняется информация об этом файле
- так происходит для 20 эпизодов, после обработки 20 эпизодов скрипт завершается
Код есть, и я написал yaml файл чтобы этот код выполнялся через GitHub Actions раз в полчаса:
- GitHub Actions запускает этот код
- Код создает 20 json файлов
- GitHub Actions коммитит эти получившиеся 20 json файлов в репозиторий
- Через полчаса процесс повторяет для следующих 20 файлов
У меня есть некоторые нарекания про интерфейс GitHub Actions, но то как задачи запускаются — это выше всяческих похвал. Я завернул код в docker, вот GitHub Action делает docker pull базового образа за 6 секунд, а дальше 12 секунд собирает образ который мне нужен (на моем ноутбуке это же выполняется за гораздо большее время).
Итак, GitHub Actions позапускал мой код каждые полчаса и где-то через 50 запусков все mp3 файлы были обработаны и в репозитории появились файлы с нужной мне информацией.
Вот репозиторий с кодом и данными: github.com/bessarabov/radio-t-data (данные про эпизоды живут в папке "data/episodes")
Я прямо очень доволен тем что получилось. Запускать в облаке такую молотилку данных гораздо удобнее чем на собственном ноуте — пришлось бы его оставлять включенным. Плюс то что этот код запускается автоматически по крону в GitHub Actions означает что в этом репозитории будет автоматически появляться данные про новые эпизоды — красота.
Результат
Итак, в репозитории github.com/bessarabov/radio-t-data в папке "data/episodes" есть информация о длине всех выпусков подкаста Радио-Т.
Дальше беру jupyter, пишу чуть-чуть питона и получаю график с данными про длину выпуска:
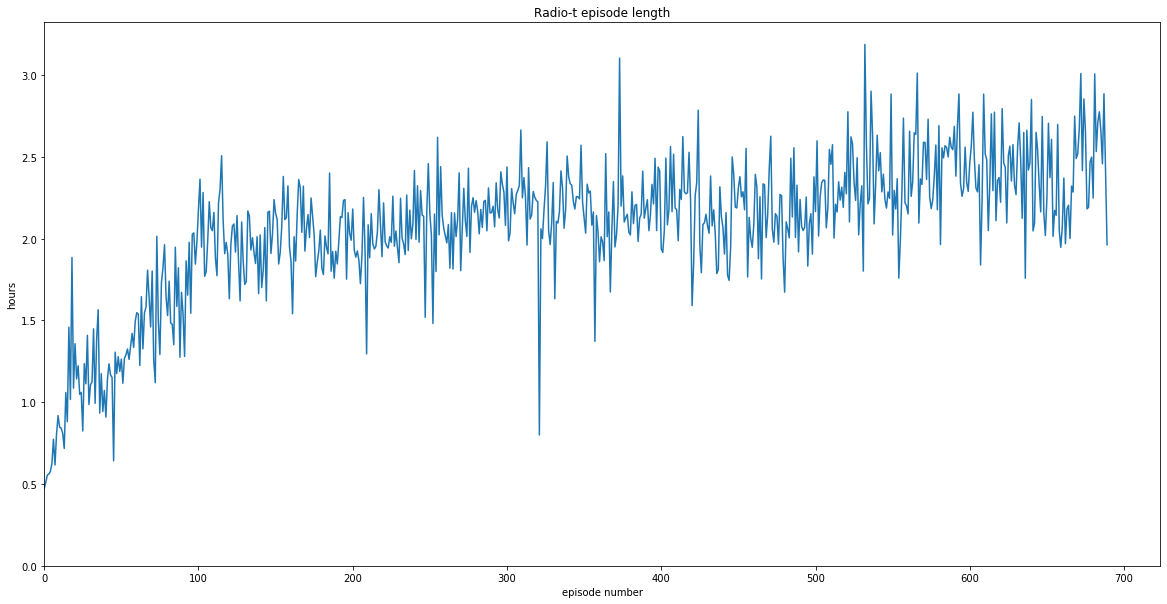
Получилось интересно: самый первый эпизод Радио-Т (с номером 0) был около получаса. Где-то к сотому выпуску дошли до двух часов и все следующие выпуски где-то и держатся около двух часов.
Но иногда некоторые выпуски выбиваются.
- Выпуск 321 — 48 минут. Выпуск был 29 декабря 2012
И есть 5 выпусков у которых длина больше трех часов. Вот номера эпизодов:
$ cat *.json | jq -r '"\( .number ) \( .file.length_seconds )"' | perl -nalE 'say $F[0] if $F[1] > 60*60*3'
373
532
566
672
681
Мне еще стало интересно, а какой размер всех файлов со всеми выпусками. Оказалось не так много. Чуть меньше 50 гигабайт.
$ cat *.json | jq '.file.size_bytes' | perl -nalE '$s += $_ }{ printf "%0.2f GB\n", $s/1024/1024/1024'
48.45 GB
И еще можно узнать полную длину вообще всех выпусков:
$ cat *.json | jq '.file.length_seconds' | perl -nalE '$s += $_ }{ printf "%0.2f days\n", $s/60/60/24'
59.45 days
Т.е. если круглыми сутками слушать Радио-Т, то за 2 месяца получится прослушать все эпизоды.
Исходный код jupyter ноутбука лежит в репозитории github.com/bessarabov/analyzing-radio-t-data.
Что еще можно сделать
Смотреть на данные — это всегда безумно интересно. То что я тут сделал — это прямо очень просто. Всего-навсего длительность каждого выпуска.
Но если обогатить данные о выпуске дополнительной информацией то можно выяснить еще что-нибудь интересненькое:
- Если добавить дату эфира (это не кажется особо сложной задачей), то можно узнать когда были пропуски, можно посмотреть есть ли сезонные колебания длительности — правда ли что зимой выпуски короче чем летом?
- Если добавить информацию о том кто был в выпуске, то можно найти тот самый единственны выпуск в котором не было Умпутуна, узнать в каком подкасте впервые появился Грей, убедится что Бобук не так уж и часто прогуливает подкаст, кто из девушек был в подкасте дольше всех, когда Алексей из редких заходов стал появляться в каждом выпуске, да и просто нарисовать красиую инфографику кто когда был в эфире.
19 февраля 2020
